GFS和普通的分布式文件系统有以下区别,如表3所示。
表3 GFS与传统分布式文件系统的区别

GFS系统由一个Master和大量块服务器构成。Master存放文件系统的所有元数据,包括名字空间、存取控制、文件分块信息、文件块的位置信息等。GFS中的文件切分为64MB的块进行存储。
在GFS文件系统中,采用冗余存储的方式来保证数据的可靠性。每份数据在系统中保存3个以上的备份。为了保证数据的一致性,对于数据的所有修改需要在所有的备份上进行,并用版本号的方式来确保所有备份处于一致的状态。
客户端不通过Master读取数据,避免了大量读操作使Master成为系统瓶颈。客户端从Master获取目标数据块的位置信息后,直接和块服务器交互进行读操作。
GFS的写操作将写操作控制信号和数据流分开,如图1所示。
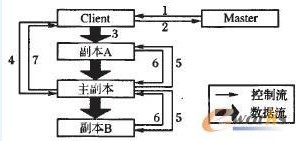
图1 写控制信号和写数据流
即客户端在获取Master的写授权后,将数据传输给所有的数据副本,在所有的数据副本都收到修改的数据后,客户端才发出写请求控制信号。在所有的数据副本更新完数据后,由主副本向客户端发出写操作完成控制信号。
当然,云计算的数据存储技术并不仅仅只是GFS,其他IT厂商,包括微软、Hadoop开发团队也在开发相应的数据管理工具。本质上是一种分布式的数据存储技术,以及与之相关的虚拟化技术,对上层屏蔽具体的物理存储器的位置、信息等。快速的数据定位、数据安全性、数据可靠性以及底层设备内存储数据量的均衡等方面都需要继续研究完善。
2.2数据管理技术
云计算系统对大数据集进行处理、分析向用户提供高效的服务。因此,数据管理技术必须能够高效地管理大数据集。其次,如何在规模巨大的数据中找到特定的数据,也是云计算数据管理技术所必须解决的问题。
云计算的特点是对海量的数据存储、读取后进行大量的分析,数据的读操作频率远大于数据的更新频率,云中的数据管理是一种读优化的数据管理。因此,云系统的数据管理往往采用数据库领域中列存储的数据管理模式。将表按列划分后存储。
云计算的数据管理技术中最著名的是谷歌提出的BigTable数据管理技术。由于采用列存储的方式管理数据,如何提高数据的更新速率以及进一步提高随机读速率是未来的数据管理技术必须解决的问题。
以BigTable为例。BigTable数据管理方式设计者——Gongle给出了如下定义:“BigTable是一种为了管理结构化数据而设计的分布式存储系统,这些数据可以扩展到非常大的规模,例如在数千台商用服务器上的达到PB(Petabytes)规模的数据。”
BigTable对数据读操作进行优化,采用列存储的方式,提高数据读取效率。BigTable管理的数据的存储结构为:->string。BigTable的基本元素是:行,列,记录板和时间戳。其中,记录板是一段行的集合体。如图2所示。
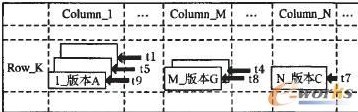
图2 BigTable的逻辑结构
BigTable中的数据项按照行关键字的字典序排列,每行动态地划分到记录板中。每个节点管理大约100个记录板。时间戳是一个64位的整数,表示数据的不同版本。列族是若干列的集合,BigTable中的存取权限控制在列族的粒度进行。
(责任编辑:adminadmin2008)





