BigTable在执行时需要三个主要的组件:链接到每个客户端的库,一个主服务器,多个记录板服务器。主服务器用于分配记录板到记录板服务器以及负载平衡,垃圾回收等。记录板服务器用于直接管理一组记录板,处理读写请求等。
为保证数据结构的高可扩展性,BigTable采用三级的层次化的方式来存储位置信息,如图3所示。
其中第一级的Chubby file中包含Root Tablet的位置,Root Tablet有且仅有一个,包含所有METADATA tablets的位置信息,每个METADATA tablets包含许多User Table的位置信息。
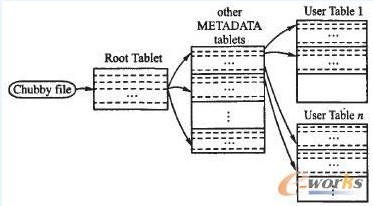
图3 BigTable中存储记录板位置信息的结构
当客户端读取数据时,首先从Chubby file中获取RootTablet的位置,并从中读取相应METADATA tablet的位置信息。接着从该METADATA tablet中读取包含目标数据位置信息的User Table的位置,然后从该User Table中读取目标数据的位置信息项。据此信息到服务器中特定位置读取数据。
这种数据管理技术虽然已经投入使用,但是仍然具有部分缺点。例如,对类似数据库中的Join操作效率太低,表内数据如何切分存储,数据类型限定为string类型过于简单等。而微软的DryadLINQ系统则将操作的对象封装为.NET类,这样有利于对数据进行各种操作,同时对Join进行了优化,得到了比BigTable+MapReduee更快的Join速率和更易用的数据操作方式。
2.3编程模型
为了使用户能更轻松地享受云计算带来的服务,让用户能利用该编程模型编写简单的程序来实现特定的目的,云计算上的编程模型必须十分简单。必须保证后台复杂的并行执行和任务调度向用户和编程人员透明。
云计算大部分采用Map—Reduce的编程模式。现在大部分IT厂商提出的“云”计划中采用的编程模型,都是基于Map—Reduce的思想开发的编程工具。
Map-Reduce不仅仅是一种编程模型,同时也是一种高效的任务调度模型。Map—Reduce这种编程模型并不仅适用于云计算,在多核和多处理器、cell processor以及异构机群上同样有良好的性能。
该编程模式仅适用于编写任务内部松耦合、能够高度并行化的程序。如何改进该编程模式,使程序员得能够轻松地编写紧耦合的程序,运行时能高效地调度和执行任务,是Map-Reduce编程模型未来的发展方向。
Map-Reduce是一种处理和产生大规模数据集的编程模型,程序员在Map函数中指定对各分块数据的处理过程,在Reduce函数中指定如何对分块数据处理的中间结果进行归约。用户只需要指定map和reduce函数来编写分布式的并行程序。当在集群上运行Map-Reduce程序时,程序员不需要关心如何将输入的数据分块、分配和调度,同时系统还将处理集群内节点失败以及节点间通信的管理等。图4给出了一个Map-Reduce程序的具体执行过程。
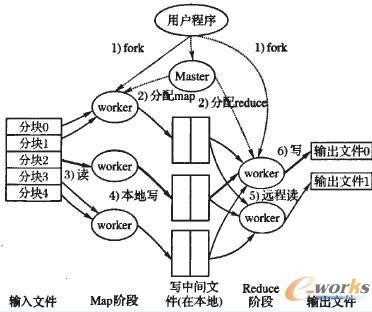
图4 Map-Reduce程序的具体执行过程
(责任编辑:adminadmin2008)