训练
现在我们有了自己的矢量和对应标签,可以将其分类为训练组和测试组。训练组大约占到样本数量的80%,剩下的就是测试组。
我们需要确保每一个标签都经过这两个组的检验,尽管这一步骤十分简单,却是极其重要不容忽略的一步。如果我们没能在每个组中包括每一个标签的样本,我们就无法让模型学会区分每个标签,并在模型建成后测试其准确性。
在我们的示例中,我们选择使用决策树集合以满足需求。决策树是一个简单的分类,针对每个特征制定二进制决策,从而将训练数据完美地分成包含大多数(或全部)标签的多个小组。决策树的最大优势就是能够基于很小数目特征制定决策,并因此为我们提供实际所需的信息。
不幸的是,这种做法总会过拟合,意思就是它们从训练数据中提取太多信息,对测试数据却完全不够。为此,我们重新整合了决策树(训练多重决策树并让其表决答案),这可以避免过拟合:
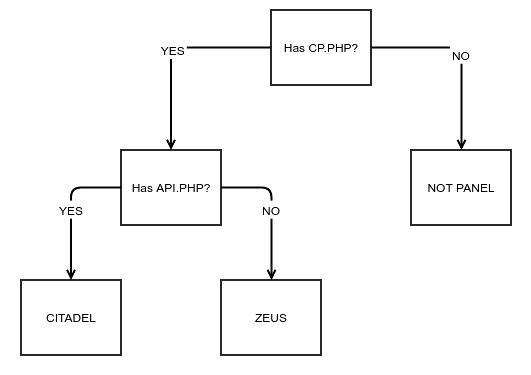
分类
一旦模型建立,我们就可以将其传递给决策树。每一个决策树都会为其分配标签,之后所有的决策树结果会结合出出现最多的最终结果。对于这种对抗性问题,用户还会看到标签的置信水平,可以说明该标签的可信程度。
例如:
Chrome扩展
一般来说,我会在浏览器中检查、搜索页面来确定僵尸网络。为此,我已经创建了一个Chrome扩展,结合这个模型可以在我访问的任何网站中自动执行这个分类方法。
在访问一个新的网站目录时,它就会自动执行请求分类(请求数目少于40个),如果发现有关僵尸网络的任何迹象会立刻警告用户。相关结果会存储下来,以便日后参考。
详情请参考:
结论
僵尸网络面板分类是个棘手的问题,但是机器学习的创新应用可以快速有效地解决它,随着数据的不断增长,这个强有力工具的价值会日益显现。它对安全专业人员和工程师的作用也会越来越大,至少目前这是个了解机器学习的好帮手。
(责任编辑:安博涛)