
01、背景
最近,偶然看到一篇论文讲如何利用机器学习从加密的网络流量中识别出恶意软件的网络流量。一开始认为这个价值很高,毕竟现在越来越多的恶意软件都开始使用TLS来躲避安全产品的检测和过滤。但是看完论文之后又有些失望,虽然文章的实验结果非常漂亮,但是有一点治标不治本的感觉,机器学习又被拿来作为一个噱头。
回顾过去的几年,机器学习在安全领域有不少应用,但其处境却一直比较尴尬:一方面,机器学习技术在业内已有不少成功的应用,大量简单的重复性劳动工作可以很好的由机器学习算法解决。但另一方面,面对一些“技术性”较高的工作,机器学习技术却又远远达不到标准。
和其他行业不同,安全行业是一个比较敏感的行业。比如做一个推荐系统,效果不好的最多也就是给用户推荐了一些他不感兴趣的内容,并不会造成太大损失;而在安全行业,假如用机器学习技术做病毒查杀,效果不好的话后果就严重了,无论是误报或漏报,对客户来说都会造成实际的或潜在的损失。
与此同时,安全行业也是一个与人博弈的行业。我们在其他领域采用机器学习算法时,大部分情况下得到数据都是“正常人”在“正常的行为”中产生的数据,因此得到的模型能够很好的投入实际应用中。而在安全领域,我们的实际对手都是一帮技术高超、思路猥琐的黑客,费尽心思构建的机器学习模型在他们眼中往往是漏洞百出、不堪一击。
如何让机器学习从学术殿堂真正走进实际应用,是每个安全研究人员值得思考的问题。本文从我所了解的一些案例和研究成果谈谈个人的看法和思考。
02、从加密的网络流量中识别恶意软件?
既然文章的开头提到了从加密的网络流量中识别恶意软件,我们先来看看这个论文的作者是如何考虑这个问题的,他们发现,在TLS握手阶段(该过程是不加密的),恶意软件所表现出的特征与正常的应用有较大区别。典型的TLS握手过程如下图所示:
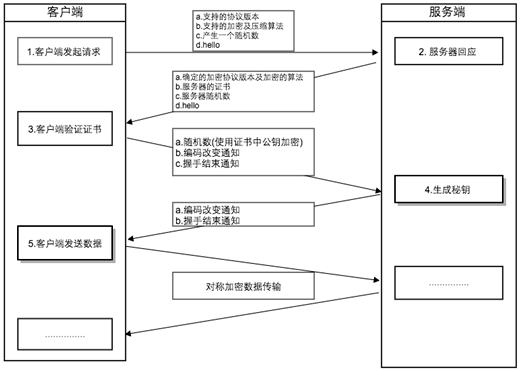
在握手的第一阶段,客户端需要告诉服务端自身所支持的协议版本、加密和压缩算法等信息,在这个过程中,正常的应用(用户能够按时更新)使用高强度加密算法和最新的TLS库,而恶意软件所使用的往往是一些较老版本协议或强度较低的加密算法。以此作为主要特征,加上网络流量本身的信息如总字节数大小、源端口与目的端口、持续时间以及网络流中包的长度和到达次序等作为辅助特征,利用机器学习算法即可训练得到一个分类模型。
看完这段描述,我的内心是崩溃的,因为该方法是把TLS握手阶段的信息作为主要特征来考虑的。道高一尺,魔高一丈。以其人之道,还治其人之身,这句话点中了机器学习的死穴,我相信凡是看到这个篇论文的黑客都会想到:以后写木马的时候一定要采用最新版本的TLS库,和服务器通信时采用加密强度较高的算法,尽量选取和正常应用类似的参数……做到以上几点,论文中提出的方法就可以当成摆设了。
03、域名生成算法中的博弈
早期的一些DGA算法所产生的域名有着比较高的辨识度,例如下面这些域名
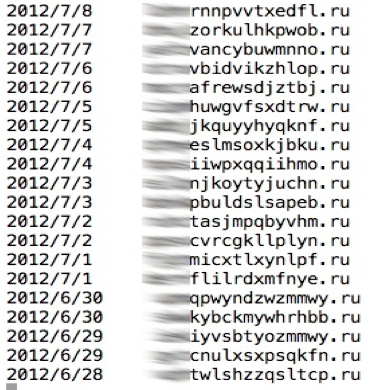
给我们的直观感受就是英文字母随机出现,而且不是常见的单词或拼音的组合,而且很难“念”出来。事实上这些特征可以用马尔可夫模型和n-gram分布很好的描述出来,早就有相应的算法实现,识别的效果也非常不错。然而,很快就出现了一些升级版的DGA算法,如下面的这个域名
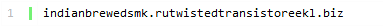
这无非就是随机找几个单词,然后拼凑在一起构成的域名,但是却完美的骗过了我们刚才提到的机器学习方法,因为这个域名无论从马尔可夫模型或是n-gram分布的角度来看,都和正常的域名没有太大的区别。唯一可疑的地方就是这个域名的长度以及几个毫无关联拼凑在一起的单词,所以额外从这两个角度考虑仍然可以亡羊补牢。
更有甚者,在今年的BSidesLV 2016上,有人提出了一种基于深度学习的DGA算法——[DeepDGA],将Alexa上收录的知名网站域名作为训练数据,送入LSTM模型和生成对抗网络(GAN, Generative Adversarial Networks)训练,最终生成的随机域名效果拔群。如下图所示(左侧是给定的输入)

从字符的分布情况上来看,也与正常网站的域名基本一致
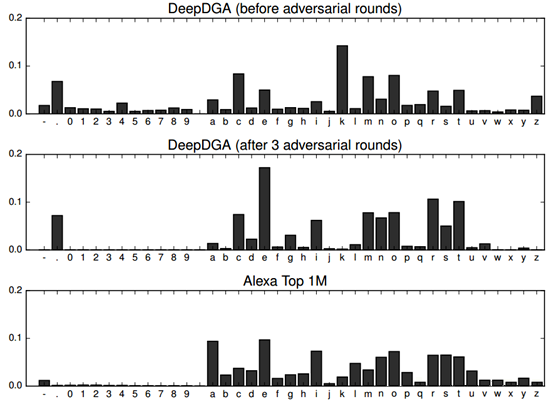
随着深度学习技术的普及,或许在不久的将来安全研究人员就可以“惊喜的”发现某个勒索软件家族开始采用这种高端的域名生成算法了……
(责任编辑:安博涛)





