本文没有公式推到,也没有代码编写,仅从算法理念和思维出发,以生活案例或日常思考方式来解读机器学习算法是什么。
(1)线性回归
回归最早是由高尔顿研究子女身高与父母身高遗传关系提出的,发现子女平均身高总是向中心回归而得名。其实“一分辛苦一分才”中就蕴含了线性回归算法思想,比较简单表现出才能与辛苦是正比关系。另外,经常听说“成功=3分才能+6分机会+1分贵人帮”,这是标准的线性回归方程,其中成功是因变量;才能、机会和贵人是自变量;而自变量前边的3、6和1是权重。
(2)K-聚类
中国有句古话是“物以类聚,人以群分”,其实已经蕴含了聚类算法的基本思想。比如说人,可以根据年龄分70后、80后、90后等;根据区域分北京、上海、广东等;根据性别分男和女。人可以根据不同特征属性进行划分,而在聚类算法中是根据不同方式来计算两个事物的距离,如欧氏距离、皮尔森相似度等。
假如根据年龄可以每10年份划分为70后、80后、90后等,也可以根据成长周期分童年、少年、青年、中年和老年。因此特征刻度大小决定了群体的范围,这反映在聚类算法中就是通过不同方法处理事物间距离,来确定事物属于哪个群体,如根据平均值、最大值等。
其中K值是表示划分群体的大小,如以区域为例,K=34,则划分为全国省份;K=7,则划分为东北,中原,华东,华北,华南,西北和西部等;K=2,则划分为南方和北方。
(3)K-邻近
中国还有句古话是“近朱者赤近墨者黑”,该句也蕴含了K-邻近算法的思想。比如判断一个人是否是有钱人,可以根据其最近联系的人群中,有钱人的比例来推测。这就需要解决两个问题,一是如何确定最近联系人,二是如何计算有钱人比例。这反映在K-邻近算法中就是首先确定不同事物样本的距离,然后确定K值的大小,根据K值内的有钱人占比,来预测未知用户的状态。
K值的大小将会直接决定预测结果,假如你有5个有钱人朋友,当K=8时,判定你为有钱人;但当K=12时,则判定你不是有钱人。因此在该算法中K的选择至关重要。
(4)朴素贝叶斯
“吃一亏长一智”反映了朴素贝叶斯算法思维,就是通过后验经验法,来对未知的预测。假如你经常买水果,发现10个青苹果里边8个都是酸的,而10个红苹果里有7个都是甜的,这种经验告诉以后再挑选苹果时,红苹果7/10是甜的,青苹果2/10是甜的,如果你喜欢甜的,那就选红苹果吧。
(5)决策树
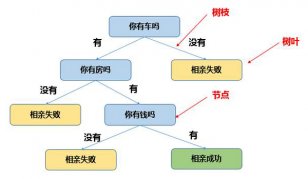
在婚恋相亲时经常被问到“你有车吗?你有房吗?你有钱吗?”,这和决策树的思维过程极其相似。决策树是由树枝,树叶,节点组成的树型结构,其中每个节点就是一个问题或特征(如你有车吗?),每个树枝是问题的走向(如有),每个节点就是答案(相亲成功)。
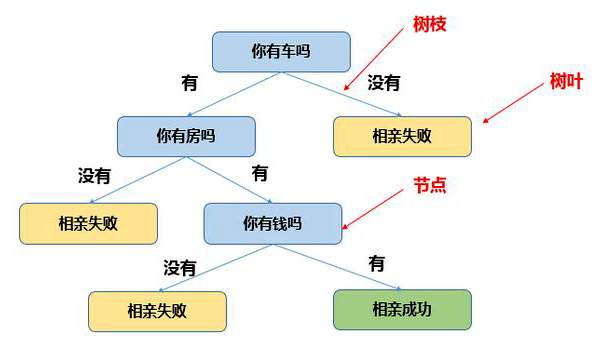
相亲决策树
(责任编辑:安博涛)